Introduced in February 2015, TechCrunch Magazine noted IPFS was “quickly spreading by word of mouth.”
It’s possibly a key component to solving deep-seated but largely unknown problems that exist in today's internet usage.
Some believe IPFS, a new tongue-twisting acronym, is a tool that’ll finally evolve the internet from central entities to a world wide web of shared information, as our online founders always envisioned.
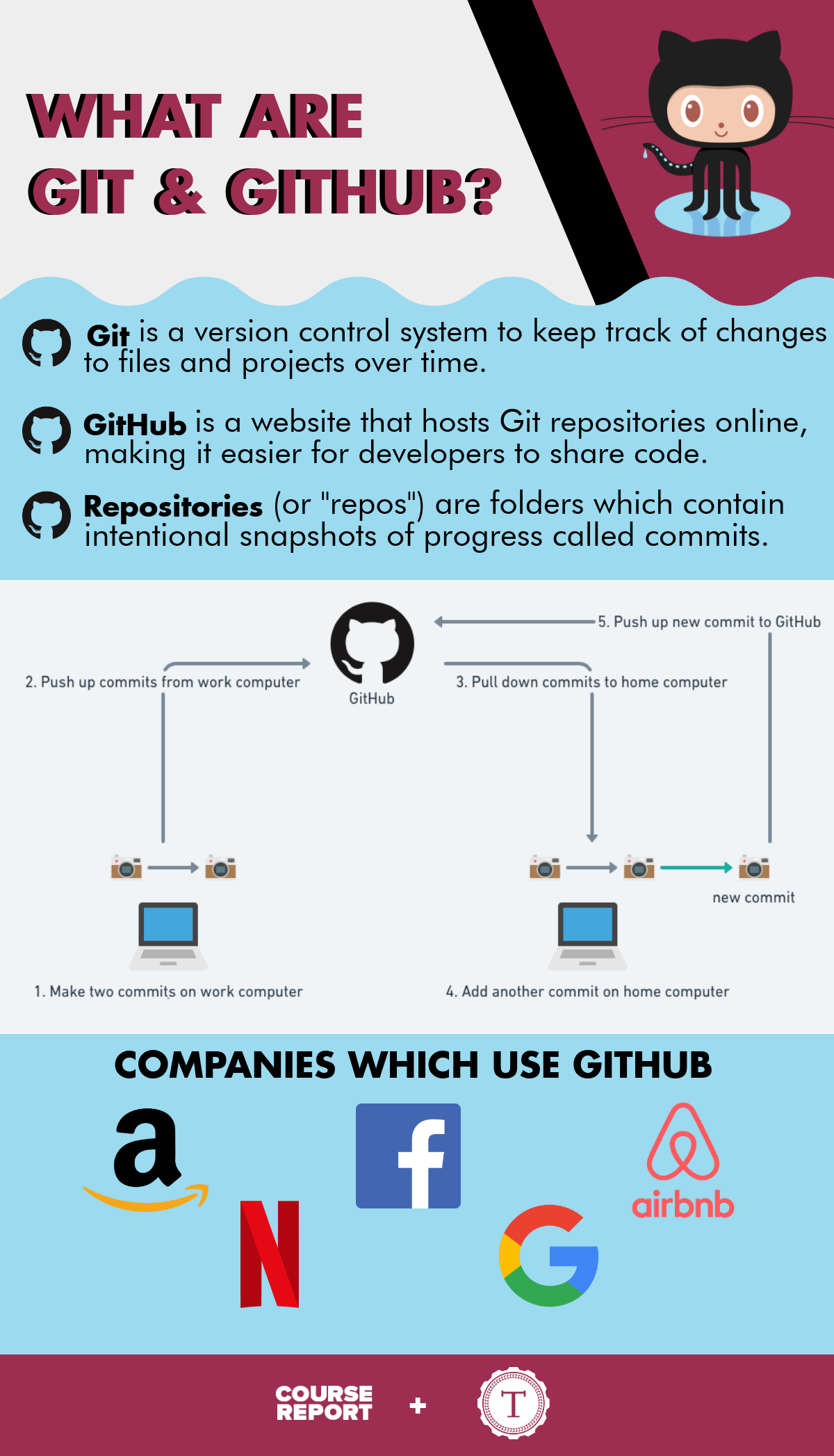
The Simple Breakdown:
IPFS = Git + BitTorrent
To understand IPFS or an Interplanetary File System, one can envision a file system that stores files and tracks versions over time, like the project Git…..
Photo Source.
{kind=link}
Git is a distributed version control system, or VCS. Developers use it to track changes to their code . When text is added, edited or deleted in any piece of code, Git tracks the changes line-by-line It’s distributed because every user has all the source code on their computer and can act as a server. Secondly, Git is backed by a content-addressable database, meaning the content in the database is immutable.
But... IPFS also incorporates how files move across a network, making it a distributed file system, such as BitTorrent.
Photo Source.
BitTorrent allows users to quickly download large files using minimum internet bandwidth. For this reason it is free to use and includes no spyware or pop-up advertising. BitTorrent’s protocol maximizes transfer speed by gathering small pieces of files desired by the user and downloads the content pieces simultaneously from other users that retain seekers content. BitTorrent is popular for freely sharing videos, programs, books, music, legal/medical records, and more. Not to mention, the downloads are much faster than other protocols.
Photo Source.
{kind=link}
Git + BitTorrent = BFF
IPFS uses BitTorrent’s approach, but applies Git’s concept and creates a new type of file system that tracks the respective versions of files from all the users in the network.
By utilizing both characteristics of these two entities, IPFS birthed a new permanent web that challenges existing internet protocols, such as HTTP.
WTF Is Wrong With HTTP? It Seems Fine To Me, TYVM.
Well, first, I’m not sure if you realized you had options. So while the thought: “The World Wide Web is actually wider…” sinks into your head, here’s a brief summary of what you’ve likely been using for some time.
Sit back for a quick lesson on HTTP, ASAP. (lol, you love the free jokes in my articles).
The internet is a collection of protocols that describe how data moves through a network. Developers adopted these protocols over time as they built applications on top of existing infrastructure. The protocol that serves as the backbone of the web is the HyperText Transfer Protocol.
HTTP, or HyperText Transfer Protocol is an application layer protocol for distributed, collaborative hypermedia systems created by Tim Berners Lee at CERN in 1989. HTTP is the foundation for data communication using hypertext files. It is currently used for most of the data transfer on the internet.
HTTP is a request-response protocol.
Since the internet boasts a vast array of resources hosted on different servers. To access these resources, a browser needs to be able to send a request to the server and display the resources. HTTP is the underlying format for structuring requests and responses for communication between client and host.
The message that is sent by a client to a server is what is known as an HTTP request. When these requests are being sent, clients can use various methods to make this request.
HTTP request methods are the assets that indicate a specific action to be performed on a given resource. Each method implements a distinct semantic, but there are some shared features.
Common Example: the Google homepage-back to the “client” or browser. This is a location-addressed protocol which means when google.com is inserted into a browser, it gets translated into an IP address belonging to a Google server, initiating a request-response cycle with that server.
WTF, We Have a 404 On HTTP! SOS!
Internet savvy, or not, I believe we have all fallen victim to an HTTP meltdown at least once in our lives.
Photo Source.
Do you recall a time in your life when you and a large group of people went to the same website at the same time?
Each individual participating in this action types the request into their online device and sends a request to that website, where a response is given.
each person is sent the same data, individually. If there’s 10,000 people trying to access a site, on the backend, there are 10k requests, and 10k responses. This sounds great, right? Problem is it’s pretty inefficient.
In a perfect world, participants should be able to leverage physical proximity to more effectively retrieve requested information.
HTTP presents another significant issue if there is a problem in the network’s line of communication, leaving the client unable to connect with the server.
This occurs if:
- A country is blocking some content
- An ISP has an outage
- Content was merely moved or deleted.
These types of broken links exist everywhere on the HTTP web.
A location-based addressing model, like HTTP, encourages the centralization of information.
It is convenient to trust a handful of applications with all our online data, but there’s a great sense of power and responsibility that comes with placing centralized providers with our precious personal and public information.
K, LMK What IPFS Is.
Simply, IPFS is an acronym for ‘InterPlanetary File System,’ which is a protocol and P2P network in a distributed system that is utilized for storing and accessing websites, applications, files and data. This system uses content-addressing to target and identify each file in a global namespace. Users can obtain and host content, much like ‘BitTorrent’.
A central server lacks some of the admirable characteristics that the IPFS network retains, being built around a decentralized system of users and operators. In an open network like IPFS, each user holds a portion of the overall data, creating and strengthening a resilient ecosystem of file sharing and storage.
Photo Source.
Any user participating in the network can serve a file by its content address, and other peers in the network can find and request content from any node with it using a distributed hash table (DHT).
Photo Source.
{kind=link}
IPSF Is G.O.A.T.! How Does It Work?
IPFS strives to create a permanent and distributed web by using a content-addressed system instead of HTTP’s location-based system.
Photo Source.
{kind=link}
HTTP requests look like: http://12.65.83.94/folder/file.txt
Where,
IPFS requests look like: /ipfs/QmR6UvrW8aUyoN5m/folder/file.txt
IPFS requests look like: /ipfs/QmR6UvrW8aUyoN5m/folder/file.txt
Rather than using a location address IPFS constructs a representation of its content to address information with a cryptographic hash. The hash represents a root object and other objects can be found in its path. HTTP “talks” to a server, but IPFS opens access to a “starting point” of data, leveraging physical proximity for better performance.
IPFS uses a Distributed Hash Table, or DHT, for data storage. Once a hash is generated, a request to ask the peer network who owns the content located at that hash. The content is then downloaded directly from the appropriate node. The data is then transferred between nodes in the network using mechanisms similar to those in BitTorrent. A content seeker on the IPFS web finds neighbors who have access to the content they want. After the content is collected, a downloading process occurs where small pieces of the content from those neighbors are stored on your PC.
But wait... that's not all! lol
In addition to the DHT and the BitTorrent protocols, IPFS uses a Dr. Merkle’s ‘Merkle Tree’. The Merkle Tree is a data structure similar to what Git uses for version control. It’s also the protocol used in Bitcoin’s blockchain technology. In Git, it's used to track different versions of source code files, whereas in IPFS is used to track targeted content across the world wide web.
….I’m Still Over Here Like, OMG! WTH Is IPFS, FFS?!
Okay, Okay- let me break it down in a real-world example.
Picture a big, green avocado! Ohhhh, They’re delicious, aren’t they?
Let’s pretend we are writing a research paper on avocados.
First, we begin by conducting a quick search for “avocados”- a Google search on my Safari browser brings me to URL results based in my North American location, the English Wikipedia site being among the top results. https://en.wikipedia.org/wiki/Avocado is the site to be exact.
When one clicks or one types the URL in their browser’s address bar, the seeking computer asks one of Wikipedia’s local computers for the avocado page. (this is a centralized platform).
Non-geeks can scroll a Google search for a few pages and feel as if their options for avocado info can quickly run dry . This is a problem. A really big problem… Think about it, I’m in America: How much can Americans possibly know about a Mexican FRUIT? (They’re in the vegetable food section here, folks! IPFS!!!… oops, wrong acronym. I meant, #smh!)
Thankfully, there’s a ‘mirror’ of Wikipedia stored on the IPFS protocol and in our searches we can access this. Although, the site address is somewhat unusual, if you’re unfamiliar with it.
When opening up an IPFS server the ‘ask’ for decentralized avocado education is just like a ‘https://’ server, requests are submitted in the address bar. But the search result page will appear something like this:/ipfs-search.com/#/search?search=avocados
And your mirrored wiki page on avocados will look close to this:/ipfs/QmPCxCiuinXrqCyQ2vymg7NcXhQVYPpz8ABVwAT1hfoH1b/wiki/Avocado.html
The IPFS-ified version of the avocado information is represented by the string of alpha-numbers found within the URL (Example: QmPCxiu…), instead of asking one of Wikipedia’s computers for the avocado information page, the IPFS network asks tons of computers to share the data that’s been requested. Using this protocol allows access to avocado information from anyone who has it, not just from Wikipedia or local searches.
IPFS Uses CID, FTW?! STFU!!!!
IPFS knows how to locate the best information on avocados (or any subject … Sorry, I love avocados!) by using a CID or content identifier, and not the information based on the location you’re searching from.
So, a CID or content identifier is a label used to highlight, note, or point material in the IPFS network. The CID does not indicate where the actual content is stored, but it forms an address based on it.
Photo Source.
{kind=link}
CIDs are special because they’re based on the content’s cryptographic hash, (see photo for simple breakdown of what a cryptographic hash is.) which implies any difference in content will produce a different CID and the same piece of content added to two different IPFS nodes using the same settings will produce exactly the same CID. The SHA-256 hashing algorithm is used in IPFS by default, but there’s support by a number of other algorithms.
Photo Source: Canva.com
Amazingly, a cryptographic hash can be used to identify any piece of data, as the hash is unique to the fixed calculated data collected.
Note: a hash has a fixed length, so the SHA-256 hash of a one-gigabyte video file is only 32 bytes. For this reason, sending and storing throughout the network is ecologically friendly, as it uses very few resources; which is critical for a distributed system like IPFS, where the data is retrieved from many different locations.
Photo Source: Canva.com
TTYL, HTTP! OMW, IPFS!
The beauty of running IPFS is, searches are posed as questions and any peer connected to the network responds. Any IPFS user that retains data or files with a particular hash sends the entire file to the information seeker. Thanks to the endless data in the world, without a short and unique identifier like the cryptographic hash function found in content addressing (CID), retrieving specialized information would not be possible, because the content itself is used to form an address, rather than information about the computer and disk location of it’s where-a-abouts.
To visualize HTTP and IPFS side by side, we can compare the two.
Photo Source.
{kind=link}
HTTP
- Uses a centralized client server
- Data not accessible if server is down or if link is broken
- Data is requested based on the address where data is hosted
- To make content publicly available one must set up a hosting server or pay to partake in the HTTP network.
- Low bandwidth related to multiple clients requesting resources from a single server, often simultaneously
- HTTP support is built into most computing machines
- HTTP is a vastly used and an established industry standard.
IPFS
- Uses a decentralized peer to peer network
- Data is shared with multiple nodes, therefore data is always accessible
- Data requested using cryptographic hash of requested data
- Every node or participant on the IPFS hosts and shares data, therefore, uploading content is free and accessible to all
- High bandwidth related to data being requested from the closest peer who retains information
- IPFS requires access using the HTTP to IPFS portal, or a manual setup to use the IPFS node on your PC (like an app)
- IPFS is an up and coming interest to investors, technologists and consumers alike.
Cool, But I’m a #WiB… How Does IPFS & BTC Tech Relate?
Related to the similarity in their underlying structure, IPFS and blockchain technology can go together like peanut butter and jelly! (It’s an American thing…)
Juan Benet, the inventor of IPFS calls Blockchain and IPFS a “great marriage.” IPFS is one of a few projects picked up by Protocol Labs, also founded by Benet. A few projects at Protocol Labs are similar to IPFS; IPLD, or Inter-Planetary Linked Data, and another called project: Filecoin.
Photo Source.
{kind=link}
Inter-Planetary Linked Data (IPLD) is a data model for distributed data structures. much like blockchain. The IPLD model allows for easy storage of and access to blockchain data using IPFS. Users willing to store IPFS data will be rewarded with a digital reward, the ‘Filecoin’.
IPLD allows users to effortlessly interact with multiple blockchains. Currently, it has been integrated with Ethereum and Bitcoin.
IPFS connects different blockchains, much like the web joins so many websites together.
These projects are quite ambitious by nature. The idea of a permanent web that is resilient and efficient was the goal of the original founders of the original internet protocol. However, over time internet uses have evolved and needs for new protocols became evident. Although it is in its early stages, IPFS could be a crucial piece of the puzzle.
Storage on blockchain is costly. According to estimates it costs $100 per GB of storage. Despite the current price of a 500GB hard drive being around $100. Source.
How can one efficiently create a versioned file system if all the files are 500x more expensive than traditional hardware? Through cryptographic hashes, of course!
When hashing a file, there’s a fixed length string unique to that file and its data. Rather than storing files, IPFS simply stores the hashes to files on the blockchain. These hashes can then be used to find the file’s actual location.
A good analogy is giving your teammates a work meeting address. Rather than physically moving the office to them, we generate a pointer (address) to where the meeting is and they come to the office.
“Mainly since blockchains have proven an inefficient and expensive way of storing data, Benet believes data, from web pages to PDFs, can be offloaded to another computing layer like IPFS. Since distributed ledgers can be put on top of IPFS for application building, he calls the two systems a “great marriage”....“If you add it to IPFS and take that hash and put it in a block, you can then use IPFS to browse the transaction and browse the file directly on the web,” Benet told CoinDesk. Benet continued: “IPFS connects all these different blockchains in a way that’s similar to how the web connects all these websites together. The same way that you can drop a link on one page that links to another page, you can drop a link in Ethereum [for example] that links to Zcash and IPFS can resolve all of that.” Source.
“Mainly since blockchains have proven an inefficient and expensive way of storing data, Benet believes data, from web pages to PDFs, can be offloaded to another computing layer like IPFS. Since distributed ledgers can be put on top of IPFS for application building, he calls the two systems a “great marriage”....“If you add it to IPFS and take that hash and put it in a block, you can then use IPFS to browse the transaction and browse the file directly on the web,” Benet told CoinDesk. Benet continued: “IPFS connects all these different blockchains in a way that’s similar to how the web connects all these websites together. The same way that you can drop a link on one page that links to another page, you can drop a link in Ethereum [for example] that links to Zcash and IPFS can resolve all of that.” Source.
Effectively, it’s a way to abstract away from cryptocurrencies.
“Imagine you’re browsing one blockchain,” Benet explained. “You can click through from one to the other, which means that you can write applications that relate the two without those applications having to understand either Ethereum or Zcash.” Source.
The idea is, if Ethereum, Zcash and other blockchains can store small amounts of data, IPFS can be a tool for linking and browsing them.
Conclusion
IPFS strives to be the new internet that would work across the globe, even planets while avoiding censorship and is infinitely bigger than the current internet. IPFS is considerably faster, far less expensive, retains more privacy features and able to withstand large scale attacks in the case of a disaster.
Amazing. Where do you see this technology taking us?
I became interested in IPFS because a project we are working on at PAC Global LLC. The technology fascinates me and I can’t wait to learn and evolve with this tech.
-END-
Thank you so much for reading. I’m out to decentralize education and bring real-world solutions to everyday consumers from the crypto and blockchain industry in efforts for a better financial future. If you’d like to find our more about our IPFS and master node projects at PAC Global, please visit our website or reach out.
PAC Global is a digital network connecting not only merchants and consumers, but business enterprise as well, with a fast, secure and more cost-effective way to send digital transactions globally.
PAC Global offers one of the world’s most powerful and secure masternode networks — enabling frictionless transactions worldwide and making them faster, safer, and cheaper. Built upon a massive distributed network and championed by blockchain pioneers, and with the total elimination of the middleman, PAC Global is truly the people’s platform for transactional and data transmissions and immutable record keeping.
Author
Alyze Sam is a Co-Founder/Director at GIVE Nation, Advisor/CCO at PAC Global and an award winning author. Sam wrote the first book on Stablecoins in 2017. The unbiased text takes complex practices and simplifies concepts for most audiences. In February 2020 Sam and her partners ‘Complete 2020 Guide to Stablecoins’ sat as the #1 New Release in Business and Money on Amazon Books. *Visuals and self-publishing done by a 16-year-old Sam personally mentors: Koosha Azim, Silicon Valley, CA. Sam’s second book, ‘Stablecoin Economy,’ a university text, released May 14th, 2020.
Edited by Adam Alonzi.
Adam is a multifaceted and genius: editor, bioinformatician, copywriter, Ethereum coder, ghost writer, commodities broker, and logistics specialist. He spends his days working on telomere research and has recently gained success with repairing damaged cells in animals. Their lab has given life to several paralyzed victims. Adam is my hero, inspiration, and a great silent leader in the tech world. Thank you for always adding value to everything you touch, my friend!
Sources: