Why bytes(str).length is not enough for getting the length of a string in Solidity, and understanding the strlen method from contracts of ens.
In the world of Javascript finding the length of a string is such an easy thing. Just dostr.length and that’s all 🤌
But strings are not so friendly to work with, in Solidity ❗. In solidity, the string is a group of characters stored inside an array and stores the data in bytes.
There is no length method in string type.
I was going through Buildspace’s bytes(str).length;🤌 but the method in this util file was a bit different:
// SPDX-License-Identifier: MIT
// Source:
// https://github.com/ensdomains/ens-contracts/blob/master/contracts/ethregistrar/StringUtils.sol
pragma solidity >=0.8.4;
library StringUtils {
/**
* @dev Returns the length of a given string
*
* @param s The string to measure the length of
* @return The length of the input string
*/
function strlen(string memory s) internal pure returns (uint256) {
uint256 len;
uint256 i = 0;
uint256 bytelength = bytes(s).length;
for (len = 0; i < bytelength; len++) {
bytes1 b = bytes(s)[i];
if (b < 0x80) {
i += 1;
} else if (b < 0xE0) {
i += 2;
} else if (b < 0xF0) {
i += 3;
} else if (b < 0xF8) {
i += 4;
} else if (b < 0xFC) {
i += 5;
} else {
i += 6;
}
}
return len;
}
}
It had this weird ‘for’ loop in code which I couldn’t understand.
So, the developer in me googled it 🕵️♀️, but all the articles I came across did this to find the length of the stringbytes(str).length;I found some similar code on Stackoverflow but no one actually explained what is happening inside.
for(len = 0; i < bytelength; len++) {
bytes1 b = bytes(s)[i];
if(b < 0x80) {
i += 1;
} else if (b < 0xE0) {
i += 2;
} else if (b < 0xF0) {
i += 3;
} else if (b < 0xF8) {
i += 4;
} else if (b < 0xFC) {
i += 5;
} else {
i += 6;
}
}
After 3 hours of 🐌 self-exploration I was able to figure it out myself (a little slow but I did it 🍾),
So I thought let’s write it down so it would be helpful for all the folks like me (not so experienced with bits, bytes 0️⃣1️⃣).
Let’s try to Unblock/Decode this
How bytes(str).length works
When we convert string to bytes this is what Solidity does:
// if we do bytes("xyz"), solidity converts it as
xyz -> 78 79 7a // 78=x, 79=y, 7a=z
ABC -> 41 42 43 // 41=A, 42=B, 43=C
Use this
If you see each character generates 1 byte that’s why when we do bytes(””).length we get the length of the string. But there are some characters for which generated bytes are more than one. For example:
€ -> e2 82 ac
For the symbol of the Euro, generated bytes are 3.
So if we try to find the length of string which includes the symbol of Euro(€) 🤑 in it, the length returned bybytes(str).length will not return the correct string length for this character as € there are 3 bytes generated:
That’s when that ‘for’ loop we've seen above comes to the rescue ⛑️
{kind=link}
Let’s iterate over this e2 82 ac
bytes array and check what’s happening inside that loop:
for(len = 0; i < bytelength; len++) {
bytes1 b = bytes(s)[i];
// b = e2 for first iteration
if(b < 0x80) {
i += 1;
} else if (b < 0xE0) {
i += 2;
} else if (b < 0xF0) {
i += 3;
} else if (b < 0xF8) {
i += 4;
} else if (b < 0xFC) {
i += 5;
} else {
i += 6;
}
}
For the first iteration b=e2there is a condition on the following line
if(b < 0x80) {
i += 1;
}
Let's decode this. This condition will basically compare decimal values of these hexadecimal characters:
0x80 -> 128
// our b is e2 at the moment, decimal value for e2 = 226
0xe2 -> 226
For regular characters, decimal conversion of their hex character will be < 128 , like for a it is 97.
So, if we check all conditions like this
for(len = 0; i < bytelength; len++) {
bytes1 b = bytes(s)[i];
if(b < 0x80) { //0x80 = 128 => 226 < 128 ❌
i += 1;
} else if (b < 0xE0) { //0xE0 = 224 => 226 < 224 ❌
i += 2;
} else if (b < 0xF0) { //0xF0 = 240 => 226 < 240 ✅
i += 3;
}
...
}
So, if our i is 3 the condition in ‘for’ loop will be 3<3, which is false and the loop will break, and the value oflen will be 1 at the moment.
And that’s it, it is the correct value for the length of string “€”
If you want to try some more strings like “€”, here is a small list of characters that occupies more than 1 byte:
€ -> e2 82 ac
à -> c3 83
¢ -> c2 a2
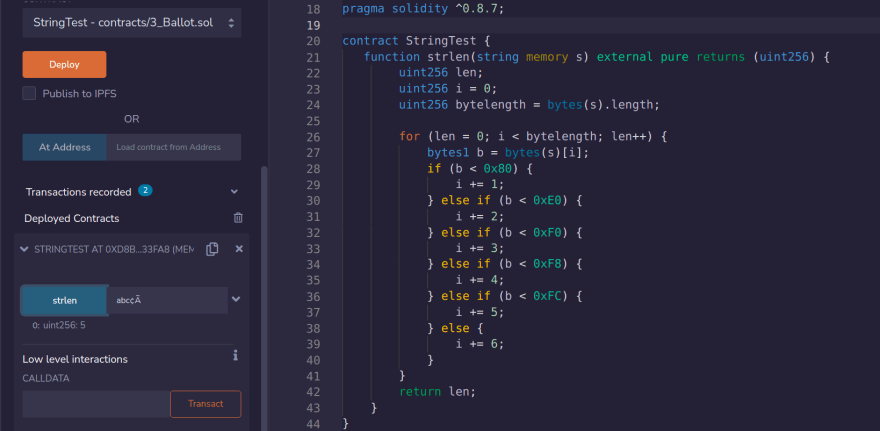
Create, a random string anything like abc¢Ã, for example, and try it out.
Ta-Da 🎉, and now it works
{kind=link}
Connect with me on
@pateldeep_eth or My DMs are open to any kind of improvement or suggestions
Originally published here.