Data in itself has no value, it actually finds its expression when it is processed right, for the right purpose using the right tools.
So when it comes to understanding the data it becomes extremely important that we are not only looking to extract obvious insights but also to identify the hidden patterns which may not be easy to find just by exploratory data analysis. To make intelligent predictions, identifying patterns and make effective recommendations our data need to be segregated into meaningful clusters.
This stream of machine learning is where we do not rely on a labeled data set which has a target variable already defined. Instead, we rely upon clustering the datasets into groups and try to make predictions about the behavior. This is called unsupervised learning.
Unsupervised learning collaborates with supervised machine learning to make our model robust and reliable. So today we will look into unsupervised learning techniques, we will go into details of
- What is Unsupervised Learning?
- Types Of Unsupervised Learning
- Understanding clustering & its types
- Hands-on on K-Means & hierarchical clustering
Let’s start this journey of learning by understanding unsupervised learning.
What Is Unsupervised Learning?
It’s a learning process where our machine has the unlabeled data set to be processed and it has to find the unknown/unseen pattern in the given data set.
It’s is a kind of self-organized Hebbian learning that helps the machine to find previously unknown patterns in data set without pre-existing labels.
Here in the above, pic, you can see that the first robot has got the data set where the required result to be tested & predicted is known to him. This is what we call supervised learning with labeled data. Whereas in the second case our robot is speaking about how it doesn’t have any clue about what is an outcome he is trying to achieve with the given data set. Here there is no pre-labeled data set fed to the robot, this is what we call Unsupervised learning.
Unlike supervised learning where we have labeled data that needs to be classified or predicted, here we don’t have any target variable which is used to measure the model outcome. Our machine self-learn from the unlabeled data set & and allows modeling probability densities of the given input.
But the question is how does our machine learn in this scenario? Well, here what we do is that we group the given data set where every group has some kind of pattern or common behavior amongst them. Let’s get into the depth of it by understanding what is clustering & types of unsupervised learning.
Unsupervised Learning Type:
Two major types of unsupervised learning methodology are:
1. Principal Component Analysis
2. Cluster Analysis(Clustering)
A. Principal Component Analysis:
Principal Component Analysis (PCA) is a statistical procedure that orthogonally transforms the original n coordinates of a data set into a new set of n coordinates called principal components. As a result of the transformation, the first principal component has the largest possible variance; each succeeding component has the highest possible variance under the constraint that it is orthogonal to (i.e., uncorrelated with) the preceding components.
I have covered PCA in-depth in my previous article, attaching the link for you all to refer and understand the concept of the same:
What Is Clustering?
Clustering is a methodology where we group or segment the given datasets where each cluster/group of data has shared attributes to extrapolate algorithmic relationships.
In this machine learning technique, the cluster of the data is not labeled, classified or categorized. The clustering of data is done based on the similarity of the feature.
Instead of responding to feedback, cluster analysis identifies commonalities in the data and reacts based on the presence or absence of such commonalities in each new piece of data.
As per Wiki,
Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense) to each other than to those in other groups (clusters). It is a main task of exploratory data mining, and a common technique for statistical data analysis, used in many fields, including machine learning, pattern recognition, image analysis, information retrieval, bioinformatics, data compression, and computer graphics.
Clustering divides objects based on unknown features. The machine chooses the best way.
Going further, we will mainly look into clustering techniques and associated algorithm with it, then we will look K-Means in detail and go hands-on with one problem statement using python & Jupyter notebook
Some of the typical Use Cases To Make Things More Clear:
- For market segmentation (types of customers, loyalty)
- To merge close points on a map
- For image compression
- To analyze and label new data
- To detect abnormal behavior
Going further, we will mainly look into clustering techniques and associated algorithms with it, then we will look at K-Means in detail and go hands-on with one problem statement using python & Jupyter notebook.
For example, you must have used Apple Photos and Google Photos in your phone, here a more complex level of clustering is involved. Your pics are clustered based on all the faces in photos to create albums of your friends. The concerned app doesn’t know how many friends you have and how they look, but it’s trying to find the common facial features, it is a typical case of unsupervised learning analysis, which involves clustering.
Similarly e-Commerce giants like amazon used customer segmentation to offer product recommendations based on group behavior and similarly of the attributes of the consumers in that particular group.
Another visual example below to help you understand the clustering mechanism
Clustering Techniques:
3 major type of clustering techniques are:
- Hierarchical Clustering
- Partitional Clustering
- Bayesian Clustering
The below diagram gives the details of the type of clustering mechanism employed in unsupervised learning.
We will mainly look into two of them in today’s journey.
- Hierarchical Clustering
- K-Means Clustering
A. Hierarchical Clustering :
Hierarchical clustering is an algorithm that groups similar objects into a cluster where each successive cluster is formed based on the previously established cluster. The endpoint is a set of clusters, where each cluster is different & distinct from each other, and also the attributes within each cluster are broadly similar to each other.
Strategies for hierarchical clustering generally fall into two types
- Agglomerative: This is a bottom-up approach: where each observation starts in its own cluster, and pairs of clusters are merged as one moves up the hierarchy.
- Divisive: This is a top-down approach: all observations start in one cluster, and splits are performed recursively as one moves down the hierarchy.
B. Partitional Clustering:
This clustering method partitions the objects into k clusters and each partition form one cluster. This method is used to optimize an objective criterion similarity function such as when the distance is a major parameter example K-means, CLARANS (Clustering Large Applications based upon randomized Search), etc. This mechanism determines all the clusters at once.
Partitional clustering decomposes a data set into a set of disjoint clusters. Given a data set of N points, a partitioning method constructs K (N ≥ K) partitions of the data, with each partition representing a cluster. That is, it classifies the data into K groups by satisfying the following requirements: (1) each group contains at least one point, and (2) each point belongs to exactly one group. Notice that for fuzzy partitioning, a point can belong to more than one group.
One of the popular partitional clustering methods is
K-Means Clustering:
K-means clustering is a method to partition n number of observations into k clusters where each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster.
The outcome of the K-means clustering algorithm is:
- The centroids of the K clusters, which can be used to label new data
- Labels for the training data (each data point is assigned to a single cluster)
How K-Means Algorithm Works:
It aims to partition a set of observations into several clusters (k), resulting in the partitioning of the data into Voronoi cells. It can be considered a method of finding out which group a certain object belongs to.
This algorithm works in the following manner:
- K points are placed into the object data space representing the initial group of centroids.
- Each object or data point is assigned to the closest k.
- After all, objects are assigned, the positions of the k centroids are recalculated.
- Steps 2 and 3 are repeated until the positions of the centroids no longer move.
Agglomerative Clustering:
It is a Bottom-up hierarchical clustering algorithm, where we treat each data point as a single cluster to start with and then successively merge (or agglomerate) pairs of clusters until all clusters have been merged into a single cluster that contains all data points. While we do this process of merging the cluster based on similarity we end up with a tree called a dendrogram
The root of the tree is the unique cluster that gathers all the samples, the leaves being the clusters with only one sample
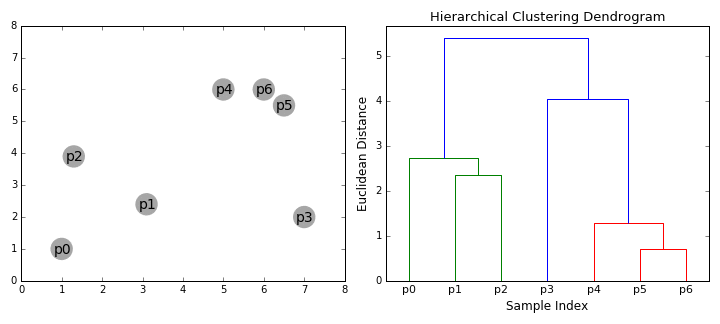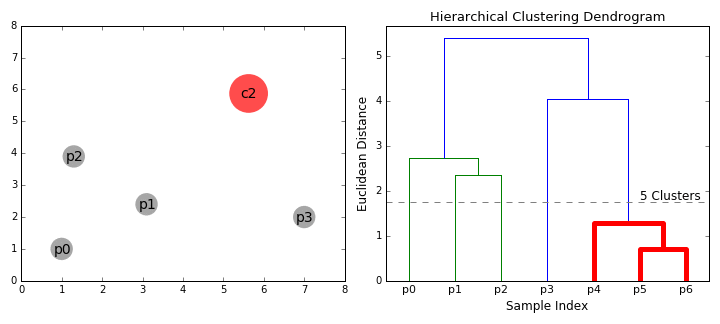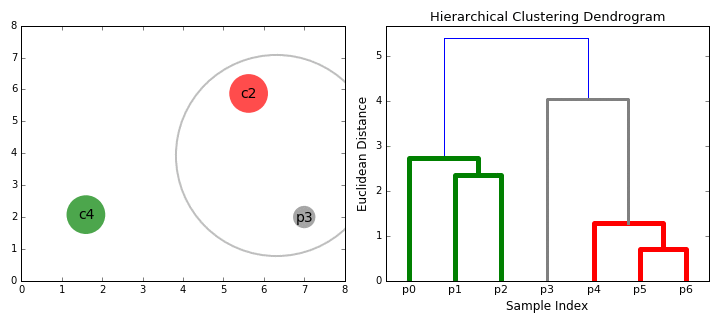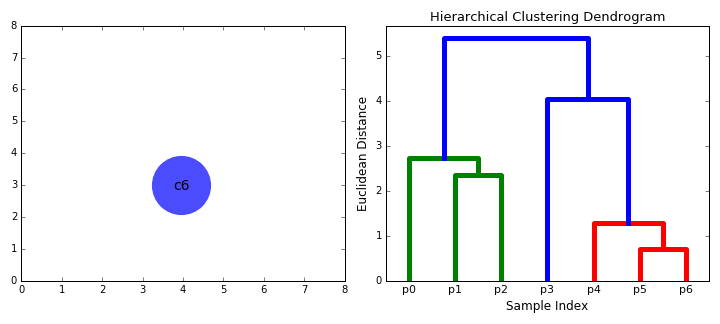{kind=link}
To understand how the above merging happens we need to understand the following key concepts:
Measures of distance (similarity)
The distance between two given clusters is computed using the distance metrics like Euclidean distance. There are other distance metrics too, like Euclidean squared, Manhattan, etc., but the choice of a distance metric purely depends on the domain and the business problem statement which one is trying to solve.
Linkage Criteria:
Once we decide to select the right distance metric, one needs to decide from which point distance is being calculated. We achieve this by using various types of linkage options. How the pairs merge in Agglomerative clustering, involves calculating a dissimilarity between each merged pair and the other sample, which is achieved by the linkage criteria.
Single Linkage:
Here the distance between two clusters is the distance between the nearest neighbors in those clusters.
Example: The distance between clusters “r” and “s” to the left is equal to the length of the arrow between their two closest points.
In single-link clustering, we consider the distance between one cluster and another cluster to be equal to the shortest distance from any member of one cluster to any member of the other cluster.
Complete Linkage:
Example: the distance between clusters “r” and “s” to the left is equal to the length of the arrow between their two furthest points
In this type of clustering (it is also called the diameter or maximum method), we consider the distance between one cluster and another cluster to be equal to the longest distance from any member of one cluster to any member of the other cluster.
Here the distance between two clusters is the distance between the furthest points in those clusters.
Average Linkage:
In average-link clustering, we consider the distance between one cluster and another cluster to be equal to the average distance from any member of one cluster to any member of the other cluster.
Example: the distance between clusters “r” and “s” to the left is equal to the average length each arrow between connecting the points of one cluster to the other.
Here the distance between two clusters is the average of the distances between all the points in those clusters.
Centroid-linkage: finds the centroid of cluster 1 and centroid of cluster 2, and then calculates the distance between the two before merging.
Divisive Clustering :
It is a top-down clustering method and is less commonly used. It works similarly to agglomerative clustering but, in the opposite direction.
Here, all observations start in one cluster, and splits are performed recursively as one moves down the hierarchy.
To Summarize: Here
- Data starts as one single combined cluster.
- The cluster splits into two distinct parts, based on some degree of similarity.
- Clusters split into two again and again until the clusters only contain a single data point.
Divisive Clustering method is rigid i.e., once a merging or splitting is done, it can never be undone
Hands-on With Hierarchical Clustering Using Python:
We will make use of Wholesale customer Data sets. This file has been sourced from UCI:
The data set refers to the clients of a wholesale distributor. It includes the annual spending in monetary units (m.u.) on diverse product categories
Note! We expect that you have installed anaconda from here, to use Jupyter as your code editor. we will be making use of Python version 3 which will come pre-loaded in anaconda installation.
Attribute Information:
- FRESH: annual spending (m.u.) on fresh products (Continuous)
- MILK: annual spending (m.u.) on milk products (Continuous)
- GROCERY: annual spending (m.u.)on grocery products (Continuous)
- FROZEN: annual spending (m.u.)on frozen products (Continuous)
- DETERGENTS_PAPER: annual spending (m.u.) on detergents and paper products (Continuous)
- DELICATESSEN: annual spending (m.u.)on and delicatessen products (Continuous);
- CHANNEL: customers Channel — Horeca (1: Hotel/Restaurant/Cafe) or Retail channel (Nominal).
Objective:
We will try to cluster this given dataset into a customer segment, which is achieved based on the purchase made by various consumers. The intent is to cluster similar customers together using a hierarchical clustering technique.
Importing Packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import warnings
import itertools
warnings.filterwarnings("ignore")
warnings.simplefilter(action='ignore', category=FutureWarning)Loading The Data Set into Pandas Dataframe:
#loading the data set
ws_df = pd.read_csv('Wholesalecustomers_data.csv')
ws_df.head(100)Here is how the output will look like:
Dropping The Data Set:
As we will not be requiring channel & region attributes in our cluster analysis let’s drop it from our data frame using the panda’s drop method.
ws_df.drop(labels=(['Channel','Region']),axis=1,inplace=True)
ws_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 440 entries, 0 to 439
Data columns (total 6 columns):
Fresh 440 non-null int64
Milk 440 non-null int64
Grocery 440 non-null int64
Frozen 440 non-null int64
Detergents_Paper 440 non-null int64
Delicassen 440 non-null int64
dtypes: int64(6)
memory usage: 20.7 KBLet’s See The Shape Our Dataframe:
ws_df.shapeoutput:
(440, 6)#Our Dataframe is of size 440 rows and 6 columns.Quick Comments:
As all the attributes above are non-null and have equal no of rows, there seem to be no missing values. All the attributes are of numerical type.
EDA: Exploratory Data Analysis:
Let’s try to eyeball all the attributes and analyze:
- How it is distributed?
- What is the statistical 5 point summary?
- And to find if there are any outliers in the given data set etc.
Descriptive Statistics:
ws_df.describe().TOutput:
Quick Observation On Descriptive Statistics Output:
- Fresh, Milk, grocery, Delicassen all have the mean and median values which are differing a lot. It means the data is skewed and is not normally distributed
- None of the attributes seems to have a normal distribution.
- There seems to be skewness in the data attributes
Univariate Data visualization of attributes:
import itertools
attr_col = [i for i in ws_df.columns if i not in 'strength']
length = len(attr_col)
cs = ["b","r","g","c","m","k"]
fig = plt.figure(figsize=(13,25))
for i,j,k in itertools.zip_longest(attr_col,range(length),cs):
plt.subplot(4,2,j+1)
ax = sns.distplot(ws_df[i],color=k,rug=True)
ax.set_facecolor("w")
plt.axvline(ws_df[i].mean(),linestyle="dashed",label="mean",color="k")
plt.legend(loc="best")
plt.title(i,color="navy")
plt.xlabel("")Output:
Quick Observation:
As can be seen above almost all the attributes are highly skewed with long positive tails on the right side.
Identifying Outliers: Using BoxPLot Analysis:
ax = sns.boxplot(data=ws_df, orient="h")Quick Observation on Outlier:
As can be seen from the above there seem to be loads of outliers in almost every attribute. Let’s Normalize the dataset using a sklearn’s normalize method.
from sklearn.preprocessing import normalize
X_std = normalize(ws_df)
X_std = pd.DataFrame(X_std, columns=ws_df.columns)
X_std.head()Output:
Hierarchical Clustering Using SciPy Package:
Plotting Dendrograms Output:
Plotting Dendrogram Cutt-Off:
The X-axis depicts data points and Y-axis represents the distance between these samples. We can see that the vertical line with maximum distance is the blue line, which helps us to decide a threshold of 6 and cut the dendrogram:
plt.figure(figsize=(15, 10))
plt.title("Dendrograms")
dend = shc.dendrogram(shc.linkage(X_std, method='ward'))
plt.axhline(y=6, color='y', linestyle='-')Output:
The yellow line is cutting the dendrogram at 6 on Y-Axis showed above.
Let’s Cluster Our Data Using Agglomerative Clustering:
from sklearn.cluster import AgglomerativeClustering
agg_clu = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward')
agg_clu.fit_predict(X_std)Output:
array([1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0,<br> 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1,<br> 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1,<br> 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0,<br> 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1,<br> 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0,<br> 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1,<br> 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1,<br> 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1,<br> 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 0,<br> 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0,<br> 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1,<br> 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0,<br> 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0,<br> 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0,<br> 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1,<br> 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0,<br> 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0,<br> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1,<br> 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1])Cluster Visualization:
Let’s visualize Milk & Grocery Data clusters using:
plt.figure(figsize=(15, 10))
plt.scatter(X_std['Milk'], X_std['Grocery'], c=agg_clu.labels_)Milk & Grocery Data Being Clustered Using Agglomerative Clustering
So you can clearly see from the above plot that we have managed to segregate milk and grocery data set as two separate clusters using unsupervised machine learning techniques called hierarchical clustering.
Hope you had great time learning with me .